
Interconnectivity must scale in line with bandwidth demand
As network traffic in data centers grow, data center interconnectivity needs to seamlessly scale to keep pace with the massive increase in demand for bandwidth. The data center interconnect application has emerged as a critical and fast-growing segment in the network landscape.
This article will explore several of the reasons for this growth, including market changes, network architecture evolution, and technology changes.
The growth of data has driven the construction of data center campuses, notably hyperscale data centers. To keep information flowing between the data centers in a single campus, each data center could be transmitting to other data centers at capacities of up to 200 Tbps today, with higher bandwidths necessary for the future (see Figure 1).
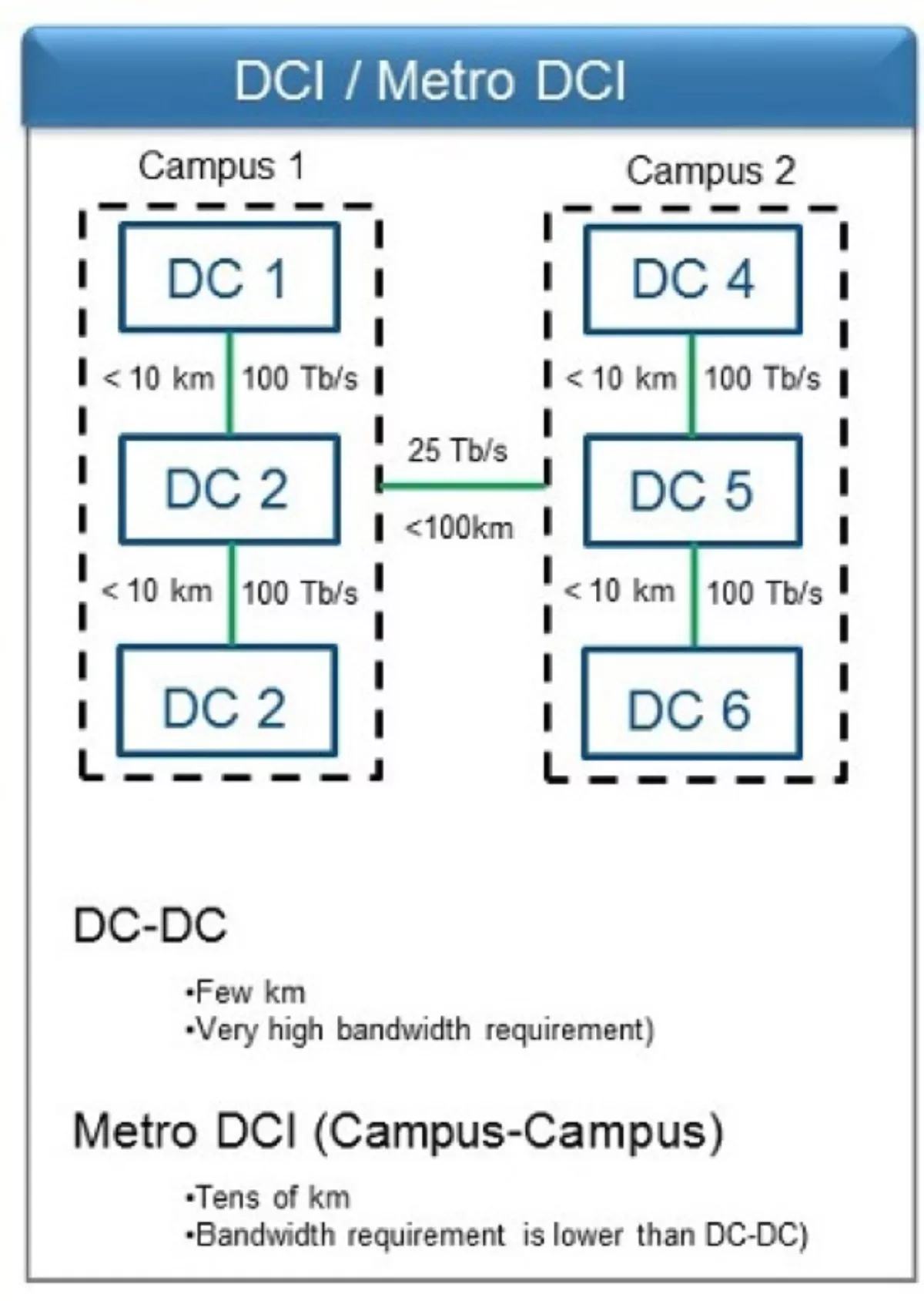
Figure 1. Conceptual campus layout. DCI requirements and distances are unique. Bandwidth demands can range as high as 100 Tbps and even 200 Tbps.
Traditionally, data center architecute is a three-tiered topology, which consists of core routers, aggregation routers, and access switches. The three-tiered architecture doesn't address the increasing workload and latency demands of hyperscale data center campus environments. Today's hyperscale data centers are migrating to spine-and-leaf architecture (see Figure 2) where the network is divided into two stages. The spine is used to aggregate and route packets towards the final destination, and the leaf is used to connect end-hosts and load balance connections across the spine.
The large spine switches are connected to a higher-level spine switch, often referred to as a campus or aggregate spine, to tie all the buildings in the campus together. By adopting flatter network architecture and high-radix switches, we expect the network to get bigger, more modular, and more scalable.
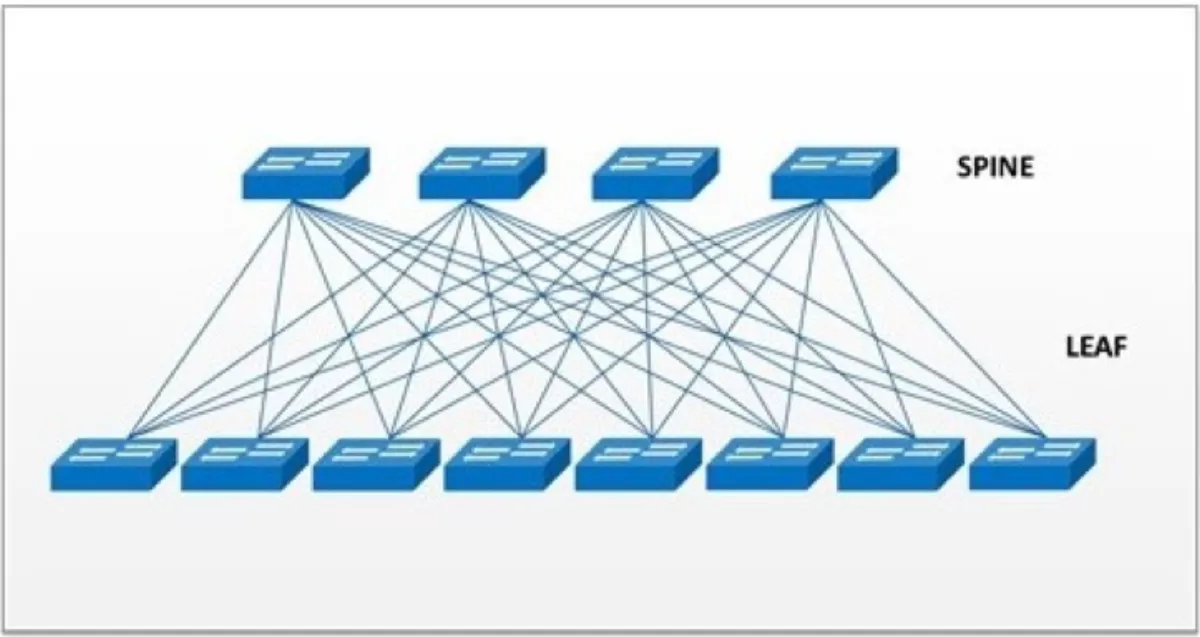
Figure 2. Spine-and-leaf architecture and high radix switch requires massive interconnects in the data center fabric.
Which mix of technology is required to deliver DCI connectivity?
Multiple approaches have been evaluated to deliver transmission rates at this level, but the prevalent model is to transmit at lower rates over many fibres. To reach 200 Tbps using this method requires more than 3000 fibres for each data center interconnection. When you consider the necessary fibres to connect each data center in a single campus, densities can easily surpass 10,000 fibres.
A common question is when to use DWDM or other technologies to increase the throughput on every fibre as opposed to constantly upgrading the number of fibres. Data Center interconnect applications up to 10 km often use 1310-nm transceivers that don't match the 1550-nm transmission wavelengths of DWDM systems. So the massive interconnects are supported by using high-fibre-count cable between data centers.
The next question becomes when to replace 1310-nm transceivers with pluggable DWDM transceivers in the edge switches by adding a mux/demux unit. The answer: when or if DWDM becomes cost-effective for these on campus data center interconnect links. Once this happens, the same bandwidth will be achieved by using DWDM transceivers associated with much lower fibre count cables.
The current prediction is that connections based on fibre-rich 1310-nm architectures will continue to be cheaper for the foreseeable future (see Figure 3).
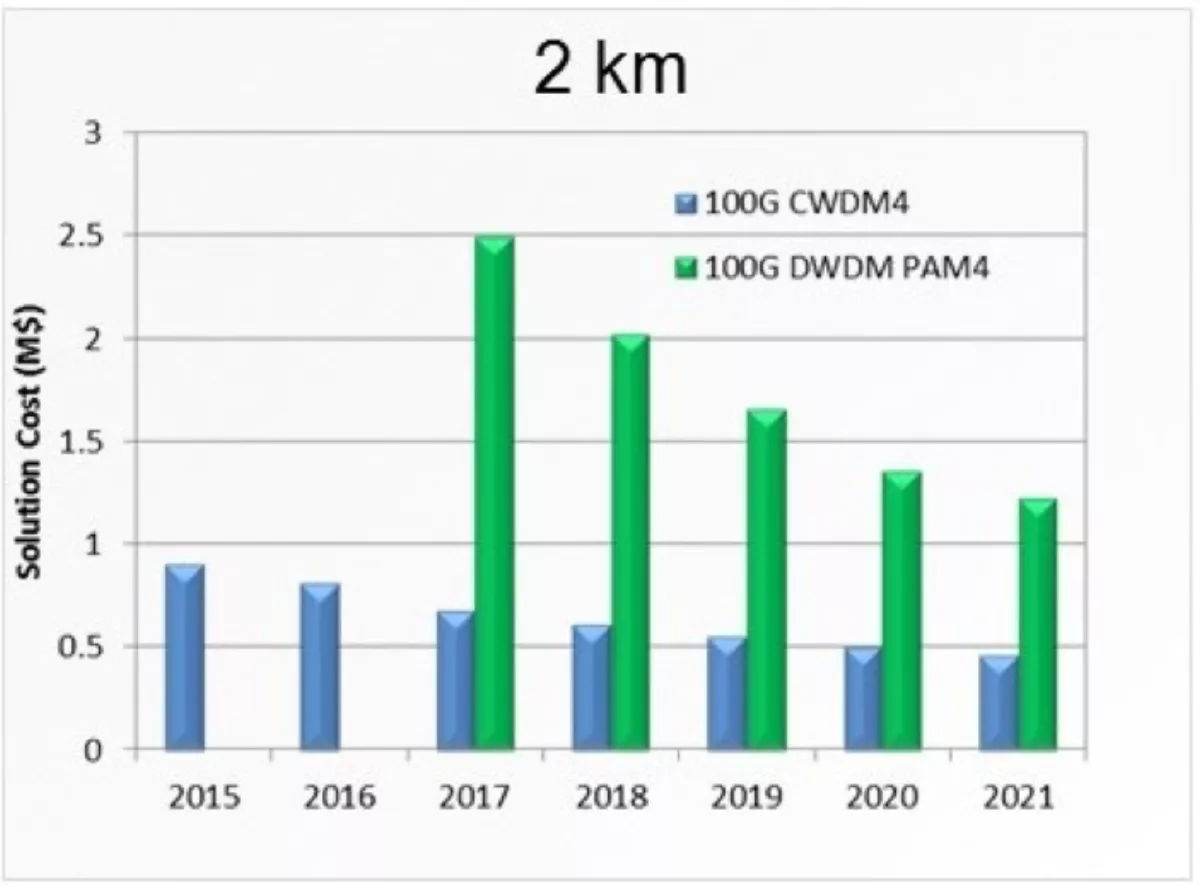
Figure 3. Pluggable DWDM transceivers vs. 100G CWDM4.
Best practices to build extreme-density networks
It is important to understand the best ways to build out extreme-density networks as these networks present new challenges in both cabling and hardware. For example, using loose tube cables and single-fibre splicing is not scalable.
New cable and ribbon designs have doubled fibre capacity from 1728 fibres to 3456 fibres within the same cable diameter or cross-section. These generally fall into two approaches: one approach uses standard matrix ribbon with more closely packable subunits, and the other uses standard cable designs with a central or slotted core design with loosely bonded net design ribbons that can fold on each other (see Figure 4).

Figure 4. Different ribbon cable designs for extreme-density applications.
Leveraging these extreme-density cable designs enables higher fibre concentration in the same duct space. Figure 5 illustrates how using different combinations of new extreme density style cables enables network owners to achieve the fibre densities hyperscale-grade data center interconnections require.

Figure 5. Using extreme-density cable designs to double fibre capacity in the same duct space.
When leveraging new ribbon cable designs, network owners should consider the hardware and connectivity options that can adequately handle and scale with these very high fibre counts. It can be easy to overwhelm existing hardware, and there are several key areas to think through as you develop your complete network.
If you are currently using 288-fibre ribbon cables in your inside plant environment, your hardware must be able to adequately accommodate 12 to 14 cables. Your hardware also must manage 288 separate ribbon splices. Using any single-fibre type cables and a single-fibre splicing method in this application is not feasible or advisable because of massive prep times and unwieldy fibre management.
Another challenge is keeping track of fibres to ensure the correct splicing. Fibres need to be labelled and sorted immediately after the cable is opened because of the magnitude of fibres that must be tracked and routed. In most installations, redoing cable prep is manageable. In the case of extreme-density networks, a mistake could cost a week's delay for just one location.
What does the future hold for extreme-density networks?
The most important factor right now is whether counts will stop at 3456 fibres, or go higher. Current trends suggest there will be requirements for fibre counts beyond 5000. With fibre packing density already approaching its physical limits, the options to reduce cable diameters in a meaningful way becomes more challenging.
Development has focused on how to provide data center interconnect links to locations spaced much farther apart, and not co-located within the same campus. In most data center campus environment, data center interconnect lengths are 2 km or less. These relatively short distances enable one cable to provide connectivity without any splicing points. With edge data centers being deployed around metropolitan areas to reduce latency times, distances can approach up to 75 km. Extreme-density cable design makes less financial sense because of the cost to connect the high number of fibres over a long distance. In these cases, more traditional DWDM systems will continue to be the preferred choice, running over fewer fibres at 40G and higher.
As network owners prepare for 5G, demand for extreme-density cabling will migrate from data center environments to access markets. It will continue to be a challenge in the industry to develop products that can scale effectively to reach the required fibre counts while not overwhelming existing duct and inside plant environments.
The next gen is oriented around the support for up to 600G per wavelength and would only be used in shorter reach metro applications with flex grid line systems capability. Data Center network operators are adopting 100G inter data center networking technologies today, and will soon be moving to adopt 400G.

