Google Cloud expands AI infrastructure with new chips
Thu, 23rd Apr 2026
Google Cloud has expanded its AI infrastructure portfolio with new chips, compute instances, networking, storage and orchestration tools. The update targets what it describes as a growing shift toward AI systems that reason and act across multiple linked tasks.
The additions include two eighth-generation Tensor Processing Units, a new A5X bare metal instance based on NVIDIA Vera Rubin NVL72, Axion N4A virtual machines using Google's Arm-based CPUs, fourth-generation Compute Engine virtual machines built on Intel and AMD processors, the Virgo Network data centre fabric, Managed Lustre storage upgrades, Z4M instances for parallel file systems, a dedicated KV Cache storage subsystem, native PyTorch support for TPUs and new Google Kubernetes Engine features.
The move reflects a broader industry effort to adapt data centre infrastructure for more complex AI workloads. Rather than handling a single prompt and response, newer systems are increasingly designed to break tasks into separate steps, coordinate across models and services, preserve context and manage repeated feedback loops. That places heavier demands on chips, memory, networks and storage.
New TPUs
Google's eighth-generation TPU line will be split into two products with different roles. TPU 8t is intended for training large models, while TPU 8i is designed for inference and reinforcement learning.
According to Google, TPU 8t offers nearly three times the compute performance of the previous generation. A single superpod contains 9,600 chips, delivers 121 exaflops of compute and includes two petabytes of shared memory connected by high-speed inter-chip links.
TPU 8i is designed to reduce latency for workloads such as reasoning and mixture-of-experts models. Google said it triples on-chip SRAM to 384 MB, increases high-bandwidth memory to 288 GB and doubles inter-chip bandwidth to 19.2 Tb/s. It also adds what Google calls a Collectives Acceleration Engine, which cuts on-chip latency by up to five times. According to the company, TPU 8i delivers 80% better performance per dollar for inference than the prior generation.
Both TPU 8t and TPU 8i are due to become available to cloud customers soon.
GPU and CPU options
Alongside its in-house chips, Google said it will be among the first cloud providers to offer instances based on NVIDIA's Vera Rubin platform when it becomes available. The A5X bare metal instance will use NVIDIA Vera Rubin NVL72.
Google is also working with NVIDIA through the Open Compute Project on the Falcon networking protocol, and A5X will include concepts drawn from that work.
For CPU-heavy parts of AI systems, such as agent orchestration, reward calculation and tool calls, Google introduced Axion-powered N4A instances based on its Arm architecture. It also updated its Compute Engine line with fourth-generation virtual machine families using Intel and AMD x86 processors.
Google said GKE Agent Sandbox with Axion N4A offers up to 30% better price-performance than comparable agent workloads on other hyperscalers, though it did not identify specific rivals.
Networking scale
One of the more significant announcements was Virgo Network, Google's latest data centre fabric for AI workloads. It provides four times the bandwidth of previous generations, according to the company.
Google said Virgo can connect 134,000 TPUs in a single fabric within one data centre and more than one million TPUs across multiple sites in one training cluster. For the new A5X systems, the same network design will support up to 80,000 GPUs in a single data centre and up to 960,000 GPUs across multiple sites.
Those figures underline the scale at which major cloud providers are now building AI clusters, as demand rises for systems that can train larger models and support more interactive inference services.
Storage changes
Storage formed another major part of the update. Google said Managed Lustre now provides 10 TB/s of bandwidth, ten times more than last year, while capacity has increased to 80 petabytes.
Managed Lustre can also use TPUDirect and RDMA so data moves directly to accelerators without passing through the host, Google said. Rapid Buckets on Google Cloud Storage, intended for checkpoints and recovery, now offers sub-millisecond latency and 20 million operations per second, according to the company.
For customers building their own storage stacks, Google introduced Z4M instances with up to 168 TiB of local SSD capacity. The systems are intended for use with established parallel file systems including Vast Data and Sycomp, and can be deployed in RDMA clusters of thousands of machines.
Software layer
On the software side, Google is previewing native PyTorch support for TPU with select customers under the name TorchTPU. The aim is to let developers run models on TPUs using native PyTorch features, including Eager Mode, without rewriting them for another framework.
Google also updated GKE for what it calls agent-native workloads. It said node start-up times are now up to four times faster and pod start-up times are down by up to 80%. Using run:AI Model Streamer and Rapid Cache in Google Cloud Storage, model loading is also said to be five times faster.
The company also added a predictive latency boost to GKE Inference Gateway. Google said this machine learning-based routing system cuts time-to-first-token latency by more than 70% without manual tuning.
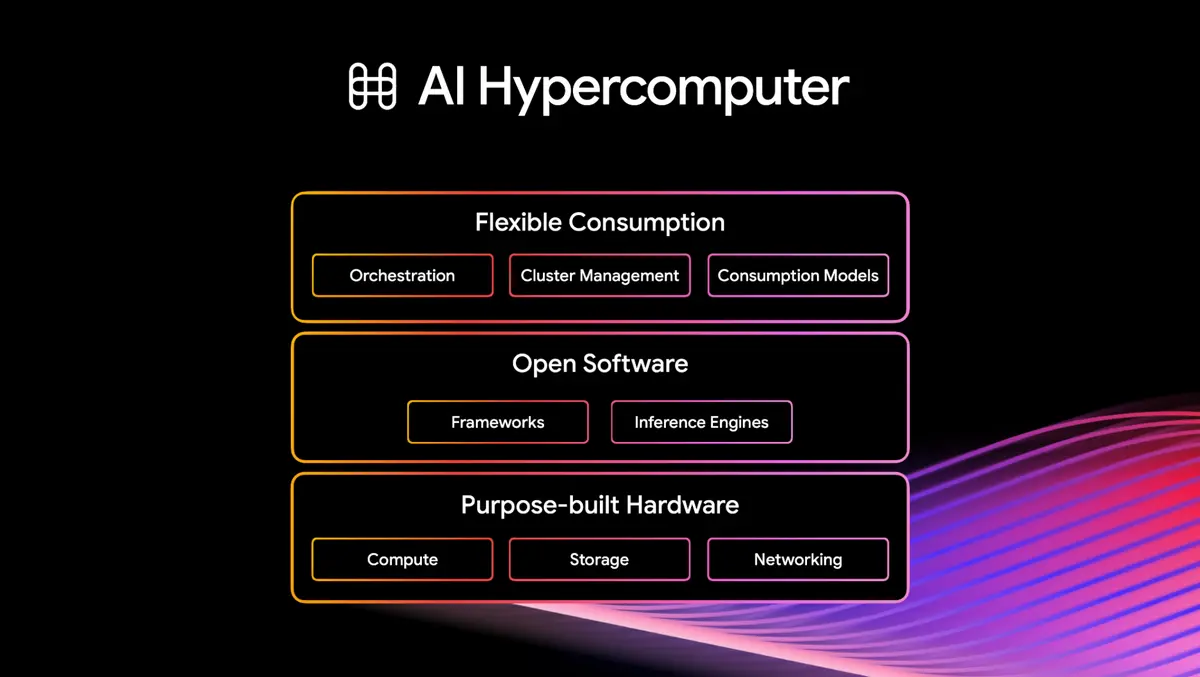
Amin Vahdat, Senior Vice President and Chief Technologist, AI and Infrastructure, and Mark Lohmeyer, Vice President and General Manager, AI and Computing Infrastructure, said: "To scale efficiently and effectively, you must move beyond manually integrating fragmented components and technologies. To deliver agentic experiences that are smart, fast, scalable, and cost-effective, you need a unified infrastructure stack that spans purpose-built hardware, open software, and flexible consumption models."